Authorship Identification Analysis
Summary
For this project, I explored authorship identification using essays by four stylistically comparable writers: David Foster Wallace, Joan Didion, Zadie Smith, and John Jeremiah Sullivan. My goal was to test whether measures such as part-of-speech (POS) distribution, lexical diversity, unique word count, word length, and hapax legomena could help distinguish one author from another even when all four were writing in the essay form.
Rather than treating authorship identification as a black-box classification task, I focused on using specific stylistic features. This approach allowed me to compare grammatical and lexical patterns across authors while also giving me experience with corpus preparation, text preprocessing, token-based feature extraction, and exploratory analysis in Python.
Methodology
Data Collection and Preparation
The text dataset was built from essays by all four authors using publicly available online sources, then downloaded the texts into local folders for analysis. The essays were drawn from public-facing venues and essay collections such as The New Yorker, The Atlantic, The Paris Review, Harper’s, and similar sites and publications. My custom Python workflow did not scrape live pages during the analysis stage but rather, processed text files that I had already saved locally, cleaned, and organized by author.
To expand the dataset, I split each essay into chunks of three paragraphs and retained only chunks between 100 and 200 words. I used this range to make the samples more comparable in length while still preserving enough local context for stylistic features (POS distribution, lexical variation, etc) to be meaningful in the analysis. I then randomly selected six chunks per author. This number was used because the author with the fewest number of samples that qualified had six, keeping the comparison as balanced as possible.
Measures Used
To analyze stylistic variation across authors, I calculated several measures for each chunk:
- Average POS usage: the average distribution of POS categories per chunk, per author.
- Average unique word count: the mean number of distinct tokens per chunk, per author.
- Lexical diversity: the proportion of unique tokens relative to total tokens in each chunk.
- Average word length: the average length of tokens used by each author.
- Hapax legomena: words that occurred only once within an author’s chunked corpus.
I used spaCy to tokenize the texts and assign POS tags, then calculated these measures from the processed token data. Because spaCy performs tokenization and POS tagging as part of its NLP pipeline, it provided a consistent basis for comparing grammatical and lexical patterns across all four authors.
Results
POS Tag Trends
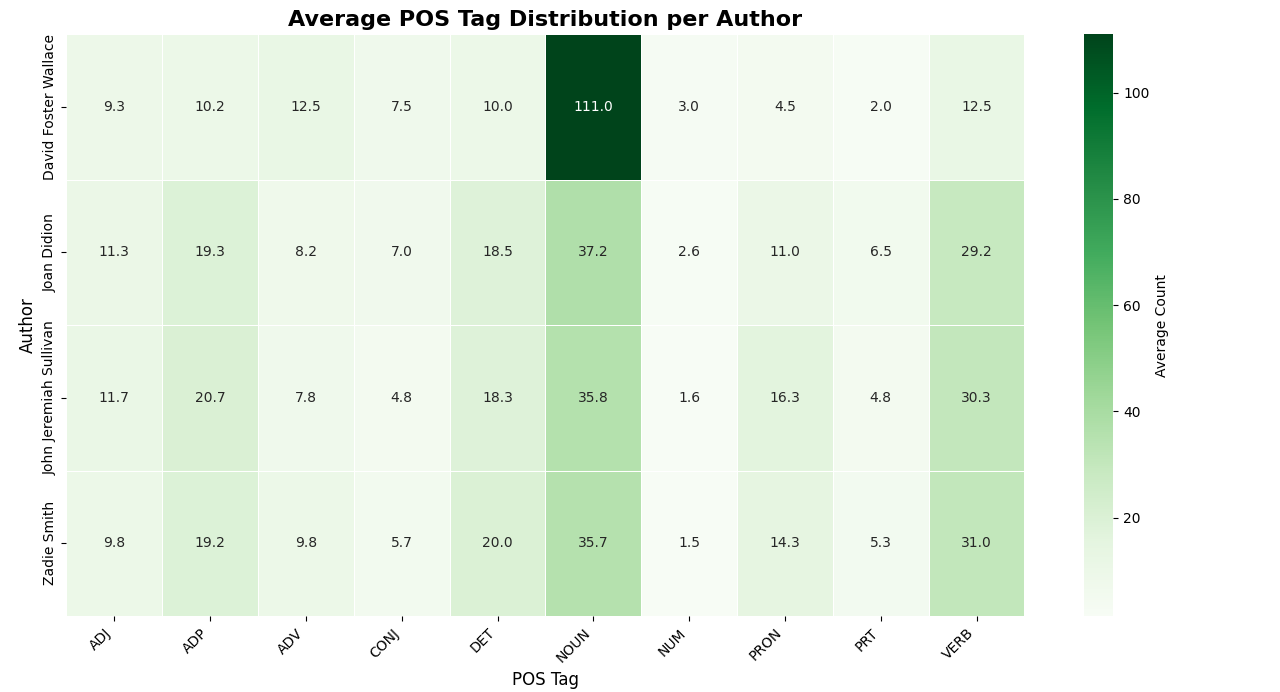
To make the POS comparison more meaningful, I interpreted POS frequencies relative to total token counts rather than relying only on raw counts. Because the chunks were similar but not identical in length, normalized POS proportions provided a fairer comparison across authors.
- David Foster Wallace showed the highest noun usage overall.
- Joan Didion, Zadie Smith, and John Jeremiah Sullivan clustered closer together in noun use.
- John Jeremiah Sullivan had the lowest adverb use; however, the non-Wallace authors were relatively close to one another in this category.
- Sullivan and Smith used more pronouns, suggesting a somewhat more personal narrative stance.
Average Unique Word Count
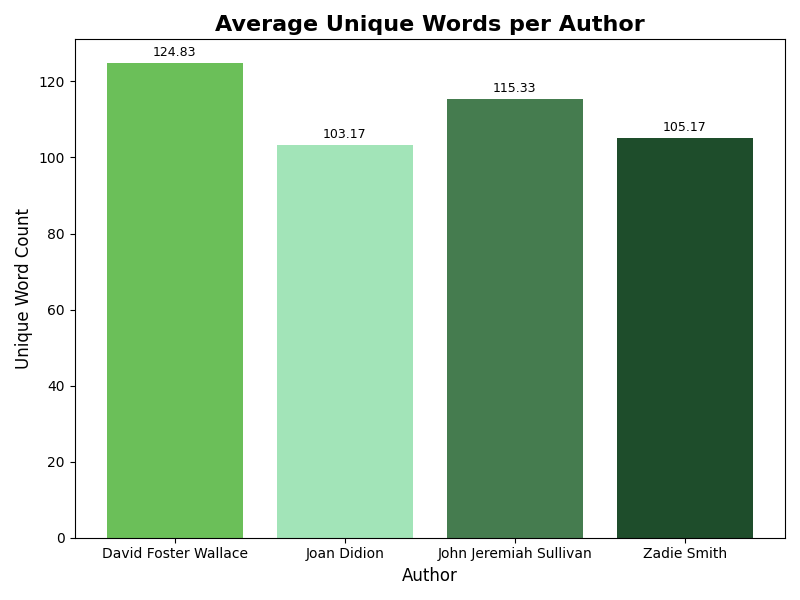
This chart compares the average number of unique words per chunk for each author. David Foster Wallace had the highest average unique word count, followed by John Jeremiah Sullivan, suggesting greater lexical range in the sampled chunks.
Average Lexical Diversity
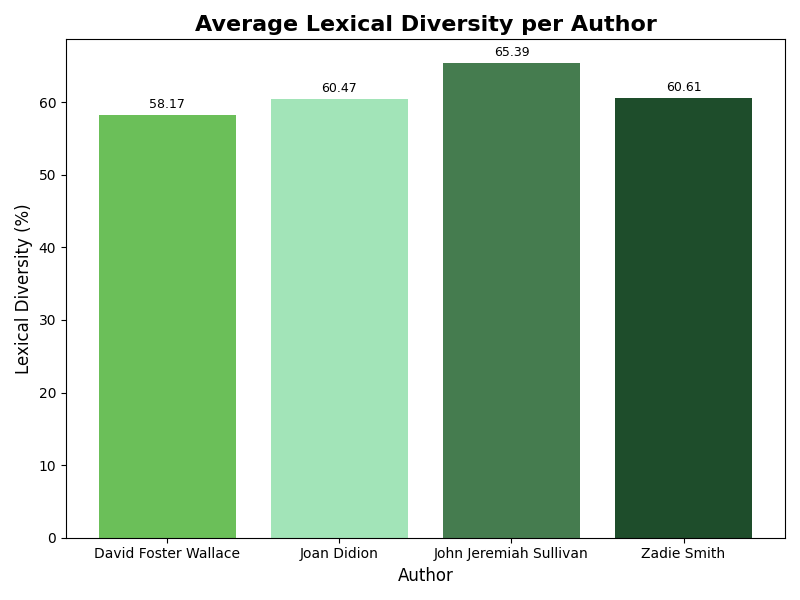
- David Foster Wallace: 61.3%
- John Jeremiah Sullivan: 63.1%
- Zadie Smith: 60.0%
- Joan Didion: 60.5%
Lexical diversity captures the proportion of unique tokens relative to total tokens in each chunk. Although Wallace had the highest raw unique word count, Sullivan showed the highest average lexical diversity, which suggests that these two measures reflect related but distinct aspects of stylistic variation.
Average Word Length
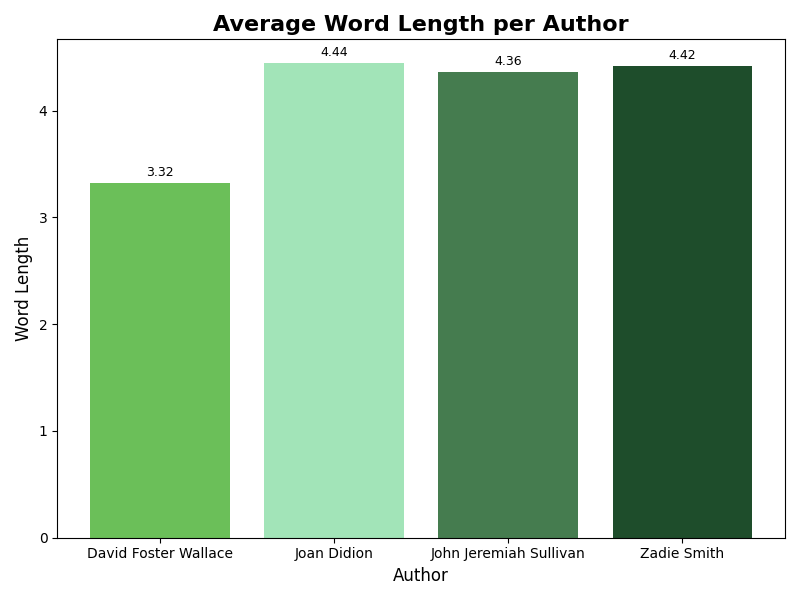
Average word length offers another simple but useful stylistic feature. While it is not strong enough on its own to identify authorship, it helps build a fuller stylistic profile when interpreted alongside the other measures. This could be helpful in creating a more robust tool for classification.
Average Hapax Legomena
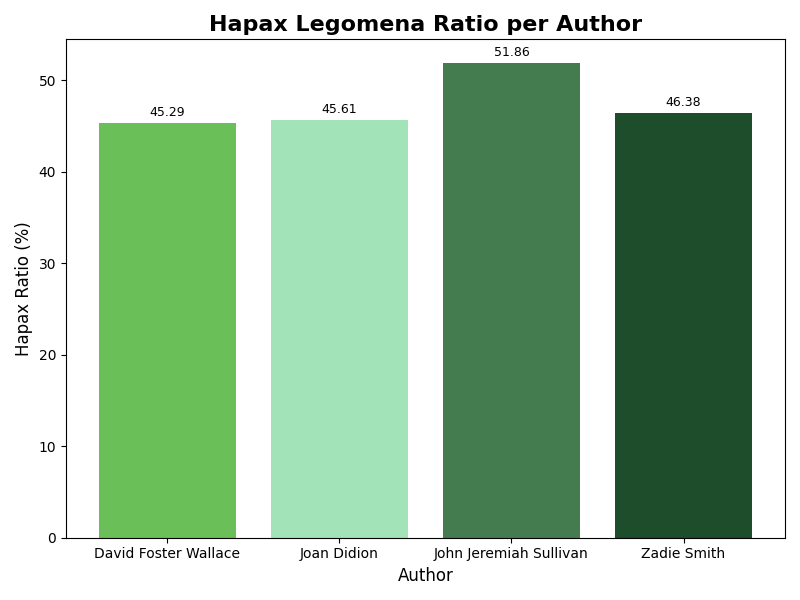
Hapax legomena are words that appear only once within a given corpus. In this project, they function best as a rough indicator of lexical rarity rather than as a definitive authorship marker, especially within such a small dataset.
Interpretation and Limits
This project was designed as a small comparative feature-analysis study rather than as a full-scale authorship classification system. The dataset was intentionally balanced across authors, but it was still limited in size and would require larger analysis to be deemed definitive.
One important takeaway is that no single feature fully separated the four authors. Instead, the strongest signals emerged when multiple features were considered together, including POS patterns, lexical diversity, unique word counts, and low-frequency vocabulary.
If I extended this project, I would increase the number of chunks per author, document preprocessing decisions even more explicitly, and compare this feature-based approach with a simple classification model. That would make it easier to test how much predictive value these stylistic measures actually provide beyond descriptive comparison.
Code
The full project code is available on GitHub: View on GitHub