Authorship Identification Analysis
Summary
For this project, I explored authorship identification using essays by four stylistically similar writers: David Foster Wallace, Joan Didion, Zadie Smith, and John Jeremiah Sullivan. While these authors have some similarities in their writing, my goal was to determine whether measures such as unique word count, part-of-speech (POS) distribution, word length, lexical diversity, sentence length and Hapax Legomana can be used to identify an author.
Methodology
Data Collection and Preparation
I selected a set of essays for each author based on availability, scraping text using a simple custom script. Some sources did not permit scraping, resulting in fewer essays for certain authors. To expand the dataset, I split each essay into chunks of three paragraphs. Chunks with word counts between 100 and 200 words were kept. To ensure balanced comparison, I randomly selected six chunks per author, based on the author with the fewest qualifying chunks (meaning that it matched my requirement of 100-200 words).
Measures Used
To investigate stylistic variation across authors, I calculated several measures for each chunk:
- Average Part-of-speech usage: The average number of each part of speech used per chunk, per author.
- Average Unique Word Count: the average of unique words per chunk, per author.
- Lexical diversity, calculated as:
- Lexical Diversity: (Number of unique tokens / Total tokens) * 100
- Average sentence length per author
- Hapax Legomana: the number of words that are used only once per author
Results
POS Tag Trends
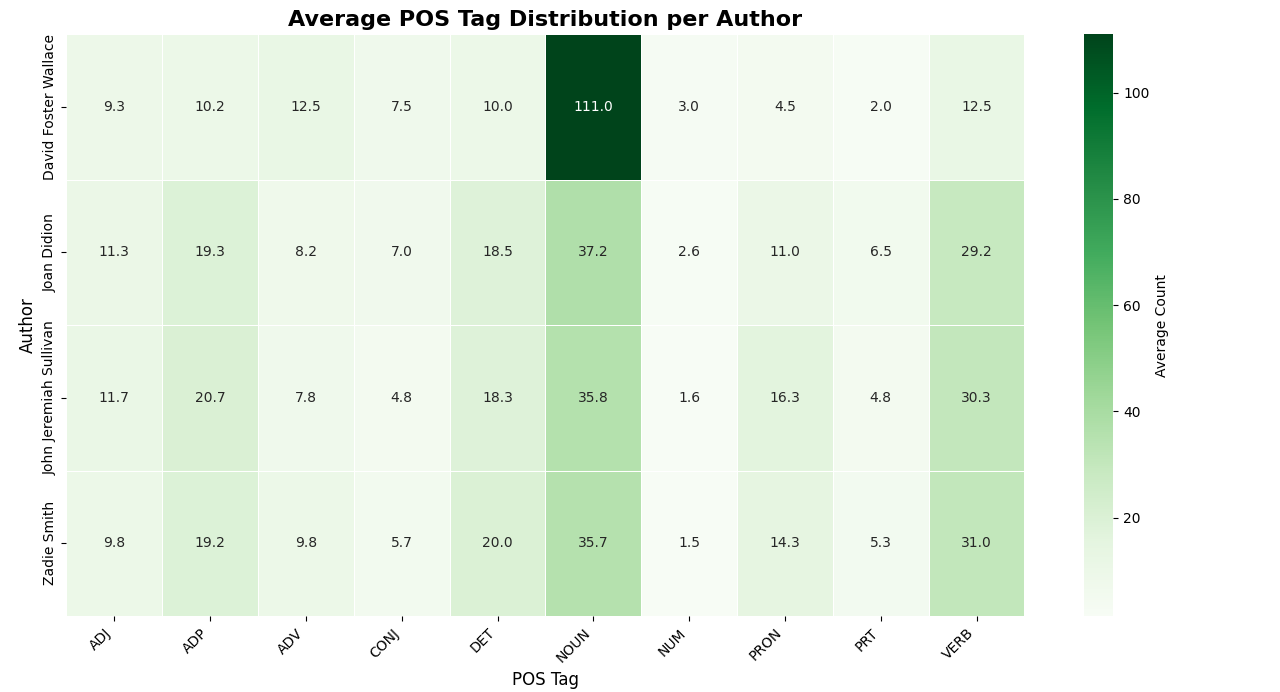
Notable patterns:
- David Foster Wallace had a significantly higher average count of nouns per essay, at 111.
- Joan Didion, John Jeremiah Sullivan, and Zadie Smith had lower noun counts and were all within a very close range of one another:
- Joan Didion: 37.2
- Zadie Smith: 35.8
- John Jeremiah Sullivan: 42.5
- John Jeremiah Sullivan the lowest adverb use (7.8), however, you will note that all of the authors aside from David Foster Wallace have relatively close counts of adverb use.
- Sullivan and Smith used more pronouns—potentially indicating a more personal narrative style.
- Didion and Wallace had higher noun counts per chunk.
Lexical Measures
Average Unique Word Count per Chunk
- David Foster Wallace: 132
- John Jeremiah Sullivan: 110.8
- Zadie Smith: 102.8
- Joan Didion: 100.3
Average Lexical Diversity
- David Foster Wallace: 61.3%
- John Jeremiah Sullivan: 63.1%
- Zadie Smith: 60%
- Joan Didion: 60.5%
Wallace and Sullivan exhibited slightly higher lexical diversity, with Didion and Smith clustering slightly lower. These subtle distinctions suggest that lexical features may offer some predictive power, though the dataset is small.
Code: View on GitHub