Bridging the Digital Divide:
Where Do We Stand?
Overview
During my internship with XRI Global, I contributed to a project focused on improving access to language technology data for low-resource and underrepresented languages. The goal was to create a structured, searchable database that would help researchers, developers, and advocates identify what kinds of language technology support already existed for a given language, including automatic speech recognition, machine translation, text-to-speech, and related metadata.
The project brought together work that is often scattered across separate workflows: data collection, metadata design, relational modeling, cleanup of inconsistent public resource information, and communication of results through a user-facing interface. My role centered on database design, data standardization, workflow support, and technical documentation, with additional exposure to multilingual data processing and evaluation work carried out across the broader team.
Project Goals
The core objective of Bridging the Digital Divide was to make dispersed and fragmented language data and trained models easier to find and use. Public resources for lower-resource languages are often spread across repositories, papers, model hubs, and organizational websites, which makes it difficult to answer practical questions such as: Does this language have ASR data? Is there a publicly available MT model? Are evaluation metrics reported consistently? Which language pairs appear to have meaningful support, and which are still largely undocumented?
To support those questions, the project needed a back-end structure that could represent languages, language families, language subfamilies, translation pairs, and supporting source metrics in a consistent format. A useful system also had to handle missing values, uneven naming conventions, inconsistent language identifiers, and data gathered from multiple public sources.
My Role
My main contribution was helping design and document a relational database that could support both structured storage and downstream querying, especially for use within a GUI-based tool. I worked on schema planning, metadata cleanup, standardization of labels and identifiers, and documentation so that the resource could be maintained and extended rather than treated as a one-off spreadsheet or static list.
More specifically, I helped organize language-level metadata, family and subfamily relationships, translation-pair records, and availability flags for ASR, NMT, and TTS resources. I also contributed to documentation that made the database structure more legible for collaborators and future maintainers, which was important because a resource like this is only useful if other people can understand how the data was organized and updated.
Database Design
One of the strongest technical aspects of the project was the move from loosely organized resource tracking to a relational structure. The database included core tables such as continent, languagefamily, languagesubfamily, languagenew, nmtpairs, and nmtpairssource, which allowed the project to connect language metadata, model availability, translation-pair information, and evaluation metrics.
For example, the languagenew table stores fields such as language name, ISO code, Glottocode, family and subfamily identifiers, continent identifier, geographic coordinates, ASR availability, ASR hours, NMT availability, TTS availability, and a count of NMT pairs. The nmtpairssource table stores translation-pair source and target tags as well as metrics like chrF++ and spBLEU, making it possible to trace not only whether translation support existed, but also how that support was measured.
This schema let the project represent multiple layers of information in one system: descriptive linguistic metadata, geographic metadata, model availability with links, and translation-pair performance data. Compared with a flat spreadsheet, the relational design reduced duplication, made updates more systematic, and supported more flexible querying for both individual languages and broader families or regions.
Sample Records
In the languagenew table, sample entries include languages such as Amharic (amh), Hausa (hau), Igbo (ibo), Yoruba (yor), Xhosa (xho), Kinyarwanda (kin), and Shona (sna), alongside fields indicating whether ASR or NMT support was available and, in some cases, estimated ASR hours.
The database also includes family-level metadata such as Afro-Asiatic, Indo-European, Austronesian, Sino-Tibetan, and Dravidian in languagefamily, with linked entries such as Semitic, Cushitic, Volta-Congo, and South Dravidian in languagesubfamily. This made it possible to organize languages both as individual records and as part of broader genealogical groupings, which improved browsing and comparative analysis.
Schema Overview
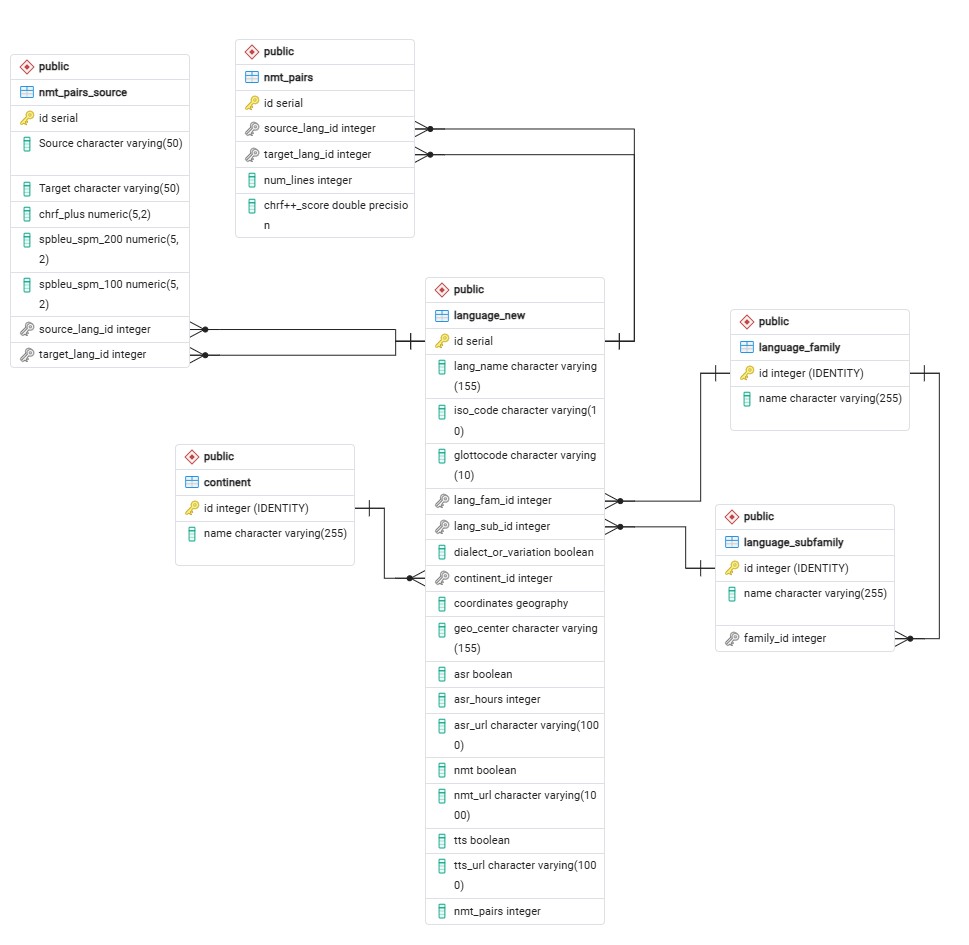
A cleaned version of the relational schema is also available in the related GitHub Repository: schema.sql
| Table | Primary Key | Key Fields | Purpose |
|---|---|---|---|
continent | id | name | Regions such as Africa and Asia |
languagefamily | id | name | Language families such as Afro-Asiatic and Indo-European |
languagesubfamily | id | name, familyid | Subfamilies such as Cushitic and Kwa |
languagenew | id | isocode, glottocode, coordinates, asrhours | Core language metadata for 55+ languages |
nmtpairs | id | sourcelangid, targetlangid, chrfscore | NMT translation-pair summary data |
nmtpairssource | id | source, target, chrfplus | NMT model metrics with 38K+ rows |
Workflow and Data Cleaning
A major challenge in the project was that public language resource information is rarely standardized. Language names, script tags, source URLs, and model descriptions can vary across repositories, and some resources report detailed metrics while others provide only minimal documentation.
To make the data queryable, I helped standardize identifiers, reconcile naming differences, and organize values into fields that could be compared more reliably. This included working with language codes, family metadata, model availability flags, and translation-pair records, as well as documenting assumptions so that later contributors could understand how ambiguous or incomplete cases had been handled.
This cleanup work improved the consistency of the database and made it easier to query languages by metadata, available technologies, and translation support. It also reduced the amount of manual interpretation required when comparing records drawn from multiple public sources.
Tools and Technical Skills
This project let me apply several skills from the M.S. in Human Language Technology in a practical setting. I worked with SQL and PostgreSQL for relational modeling, Python-based workflows for data preparation and processing, and data science libraries referenced in the project workflow, including pandas, spaCy, and scikit-learn.
The internship also required professional coordination. This included defining scope, collaborating with supervisors and teammates, keeping documentation legible for multiple audiences, and adapting the project as requirements changed. Those professional skills are harder to show in a short portfolio summary, but they were central to the success of the work.
Code Snippet
The query below shows how I joined the core language metadata table to family and subfamily lookup tables so the resource could return structured information about language support for individual languages.
SELECT
l.langname,
l.isocode,
l.asr,
l.asrhours,
l.nmt,
lf.name AS language_family,
ls.name AS language_subfamily
FROM public.languagenew l
LEFT JOIN public.languagefamily lf
ON l.langfamid = lf.id
LEFT JOIN public.languagesubfamily ls
ON l.langsubid = ls.id
WHERE l.isocode IN ('amh', 'hau', 'ibo', 'yor')
ORDER BY l.langname;The code below shows the query written to show languages with both ASR and NMT support:
SELECT
l.langname,
l.isocode,
l.asr,
l.asrhours,
l.nmt,
lf.name AS language_family
FROM public.languagenew l
LEFT JOIN public.languagefamily lf
ON l.langfamid = lf.id
WHERE l.asr = true
AND l.nmt = true
ORDER BY l.langname;The query below is used by the site to find African languages and their technology support
SELECT
l.langname,
l.isocode,
c.name AS continent,
l.asr,
l.nmt,
l.tts
FROM public.languagenew l
LEFT JOIN public.continent c
ON l.continentid = c.id
WHERE c.name = 'Africa'
ORDER BY l.langname;This query shows language pairs with the highest chrF++ scores:
SELECT
source,
target,
chrfplus,
spbleuspm200,
spbleuspm100
FROM public.nmtpairssource
WHERE chrfplus IS NOT NULL
ORDER BY chrfplus DESC
LIMIT 10;Project Outcome
The project resulted in a structured database and a public-facing interface intended to help users explore which languages had documented support for technologies such as ASR, NMT, and TTS. It also provided a more organized foundation for tracking language-resource coverage across families, regions, and translation pairs.
The original deployment is no longer actively maintained. The person who had been maintaining the deployed version left the organization, and the company no longer has access to that deployment environment. As a result, the live site is no longer available in its original form.
An archived version of the project remains accessible through the Wayback Machine, which preserves the public-facing interface even though the original deployment is no longer maintained. For portfolio purposes, I am including the database structure, sample query logic, and project summary here so the underlying technical work remains visible.
The abstract for the presentation of this project at the LT4All conference appears in the 2025 Book of Abstracts: LT4All 2025 Book of Abstracts.