Bridging the Digital Divide:
Where Do We Stand?
Summary
As an intern with XRI Global, I collaborated with staff and fellow University of Arizona HLT students on a project aimed at supporting low-resource languages by improving their digital presence.
Our team inventoried existing datasets and language models from platforms like Hugging Face, GitHub, and Mozilla Common Voice. For some languages where models were not available, we trained new ones using open datasets.
My contributions included designing the underlying database schema, identifying data standards, streamlining data collection workflows, and cleaning and standardizing data.
The resulting project powers a public web interface at digitaldivide.ai (archived) which lets researchers query languages, ASR/NMT availability, and geographic coverage.
Project background
Low‑resource languages often lack accessible datasets and language models, which limits their representation in NLP and voice technology.
This project aimed to reduce that gap by creating a curated, searchable inventory of datasets and models for low‑resource languages, powered by a standardized database and a user‑friendly web interface.
Language curation & data workflow
- Processed batches of languages grouped by region or language family, and inventoried whether datasets or language‑aware LLMs already existed on platforms such as Hugging Face, GitHub, and Mozilla Common Voice.
- Added available resources to the PostgreSQL database with metadata such as language family, subfamily, region, number of speakers, translation directions, ISO codes, Glottocodes, model accuracy metrics, and provenance links.
- For languages with little or no online presence, either trained new models on open‑source data or explicitly recorded them as “no data found,” helping identify critical resource gaps.
- Standardized entries across diverse dialects and varieties by researching and assigning ISO 639‑3 codes wherever possible, following SIL’s documentation requirements and handling edge cases such as dialects, macrolanguages, and umbrella varieties that did not qualify for their own ISO 639‑3 code.
Database schema & interface
The project uses a PostgreSQL 17.1 + PostGIS schema with **6 core tables**: continent, languagefamily, languagesubfamily, languagenew (ISO codes, Glottocodes, ASR/NMT/TTs metadata), nmtpairs, and nmtpairssource (38K+ NMT evaluation metrics).
Key features: Geographic coordinates, language hierarchies, CHRF+/SpBLEU scores
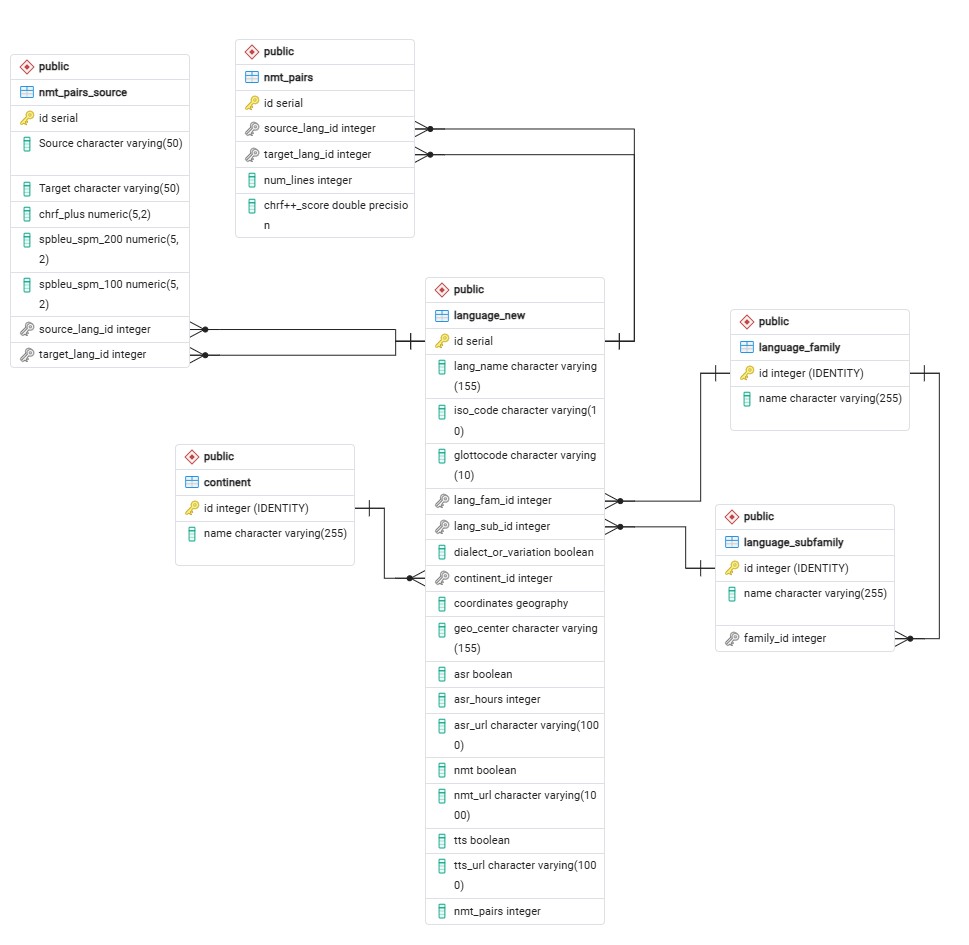
Schema overview
| Table | Primary Key | Key Fields | Purpose |
|---|---|---|---|
continent | id | name | Regions (Africa, Asia) |
languagefamily | id | name | Families (Afro-Asiatic, Indo-European) |
languagesubfamily | id | name, familyid | Subfamilies (Cushitic, Kwa) |
languagenew | id | isocode, glottocode, coordinates, asrhours | Core language metadata (55+ languages) |
nmtpairs | id | sourcelangid, chrfscore | NMT translation pairs |
nmtpairssource | id | Source, Target, chrfplus | NMT model metrics (38K+ rows) |
Learning outcomes
- Applied corpus‑linguistic and NLP concepts (e.g., language families, metadata standards) to real‑world resource‑gap analysis for low‑resource languages.
- Designed and normalized a relational schema scaling to hundreds of languages and datasets, reinforcing database design and SQL best practices.
- Developed automated workflows for language‑model curation, including ISO 639‑3 code assignment and metadata standardization.
- Documented project work in a public‑facing website and GitHub, strengthening skills in technical communication and portfolio‑style documentation.
Tools & Technologies
- Programming languages: Python, SQL
- Libraries & frameworks: spaCy, scikit‑learn, pandas, NumPy
- Database: PostgreSQL (with schema design and ERD creation)
- Language‑tech platforms: Hugging Face, GitHub, Mozilla Common Voice
- Development & collaboration: Replit, Git/GitHub, command‑line tools
- Visualization & deployment: HTML/CSS, GitHub Pages
Process & timeline
Project timeline by phase
Weeks 1–4: Planning & requirements
- Defined project goals, low‑resource language criteria, and data‑scope boundaries.
- Designed the PostgreSQL schema and agreed on metadata fields with the team.
Weeks 5–8: Database implementation
- Populated core tables (
Languages,Datasets,Models,Contributors) with metadata, ISO codes, and Glottocodes. - Built and tested initial queries joining languages, datasets, and models.
Weeks 9–12: Tool development & standardization
- Developed a Replit‑based prototype of the curation and mapping tool.
- Standardized language‑pair tags and added NMT‑specific metrics and provenance links.
Weeks 13–16: Conference & external demo
- Prepared visualizations and slides presenting the project to external audiences.
- Refined the web interface and expanded dataset coverage based on stakeholder feedback.
Weeks 17–20: Feedback & metadata expansion
- Integrated speaker population estimates and language‑status data into the schema.
- Refined UI labels and filters based on partner feedback.
Weeks 21–present: Ongoing maintenance
- Continued adding new datasets and trained models to the database.
- Resolved duplicate tags and standardized metadata to improve consistency across languages.